1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| # ChatTTS-WebUI.py
import random
import ChatTTS
import gradio as gr
import numpy as np
import torch
from ChatTTS.infer.api import refine_text, infer_code
print('启动ChatTTS WebUI......')
# WebUI设置
WEB_HOST = '127.0.0.1'
WEB_PORT = 8089
MODEL_PATH = '/Users/obullxl/PythonSpace/ChatTTS-Model'
chat = ChatTTS.Chat()
chat.load_models(
vocos_config_path=f'{MODEL_PATH}/config/vocos.yaml',
vocos_ckpt_path=f'{MODEL_PATH}/asset/Vocos.pt',
gpt_config_path=f'{MODEL_PATH}/config/gpt.yaml',
gpt_ckpt_path=f'{MODEL_PATH}/asset/GPT.pt',
decoder_config_path=f'{MODEL_PATH}/config/decoder.yaml',
decoder_ckpt_path=f'{MODEL_PATH}/asset/Decoder.pt',
tokenizer_path=f'{MODEL_PATH}/asset/tokenizer.pt',
)
def generate_seed():
new_seed = random.randint(1, 100000000)
return {
"__type__": "update",
"value": new_seed
}
def generate_audio(text, temperature, top_P, top_K, audio_seed_input, text_seed_input, refine_text_flag):
torch.manual_seed(audio_seed_input)
rand_spk = torch.randn(768)
params_infer_code = {
'spk_emb': rand_spk,
'temperature': temperature,
'top_P': top_P,
'top_K': top_K,
}
params_refine_text = {'prompt': '[oral_2][laugh_0][break_6]'}
torch.manual_seed(text_seed_input)
text_tokens = refine_text(chat.pretrain_models, text, **params_refine_text)['ids']
text_tokens = [i[i < chat.pretrain_models['tokenizer'].convert_tokens_to_ids('[break_0]')] for i in text_tokens]
text = chat.pretrain_models['tokenizer'].batch_decode(text_tokens)
# result = infer_code(chat.pretrain_models, text, **params_infer_code, return_hidden=True)
print(f'ChatTTS微调文本:{text}')
wav = chat.infer(text,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
use_decoder=True,
skip_refine_text=True,
)
audio_data = np.array(wav[0]).flatten()
sample_rate = 24000
text_data = text[0] if isinstance(text, list) else text
return [(sample_rate, audio_data), text_data]
def main():
with gr.Blocks() as demo:
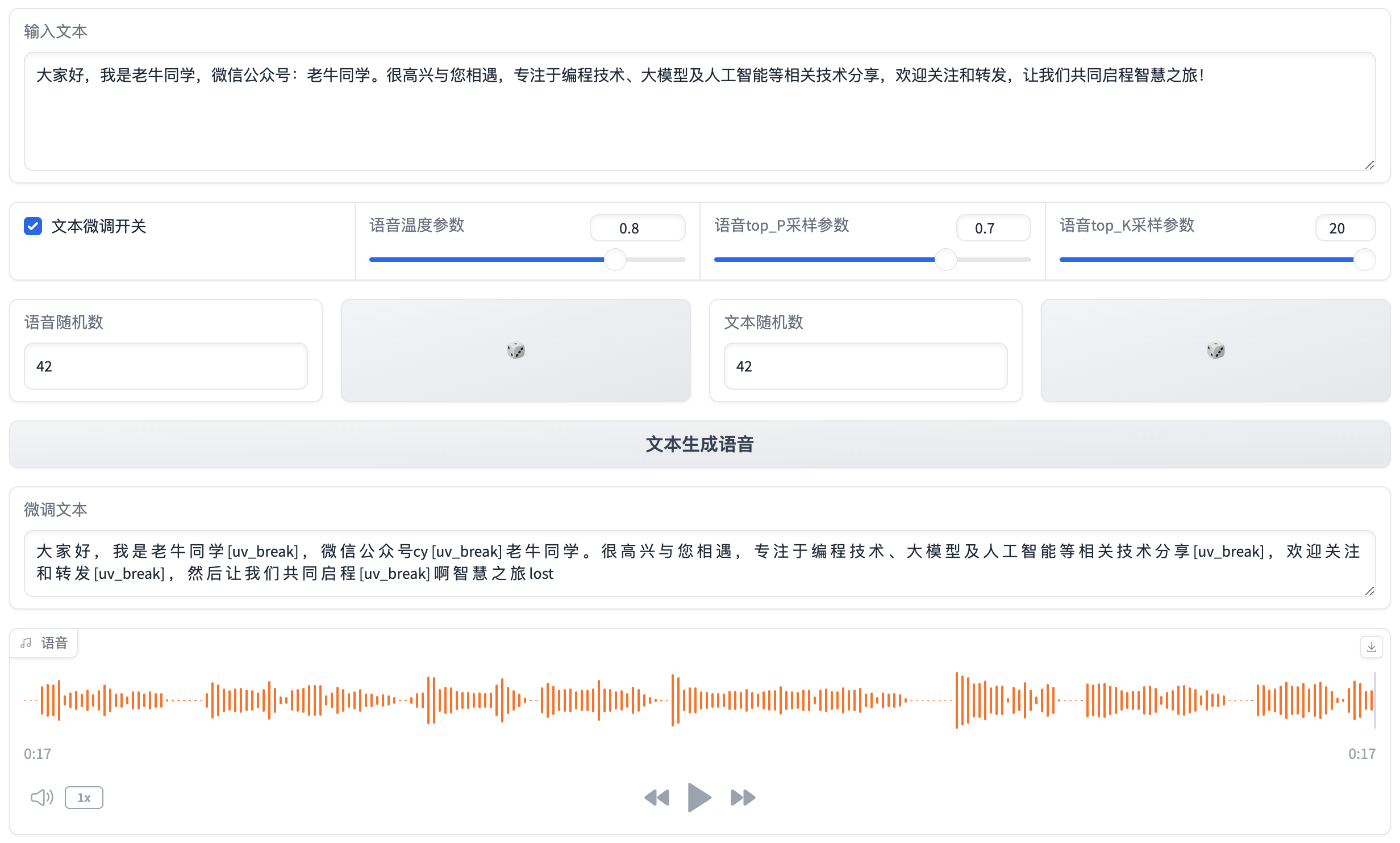
default_text = "大家好,我是老牛同学,微信公众号:老牛同学。很高兴与您相遇,专注于编程技术、大模型及人工智能等相关技术分享,欢迎关注和转发,让我们共同启程智慧之旅!"
text_input = gr.Textbox(label="输入文本", lines=4, placeholder="Please Input Text...", value=default_text)
with gr.Row():
refine_text_checkbox = gr.Checkbox(label="文本微调开关", value=True)
temperature_slider = gr.Slider(minimum=0.00001, maximum=1.0, step=0.00001, value=0.8, label="语音温度参数")
top_p_slider = gr.Slider(minimum=0.1, maximum=0.9, step=0.05, value=0.7, label="语音top_P采样参数")
top_k_slider = gr.Slider(minimum=1, maximum=20, step=1, value=20, label="语音top_K采样参数")
with gr.Row():
audio_seed_input = gr.Number(value=42, label="语音随机数")
generate_audio_seed = gr.Button("\U0001F3B2")
text_seed_input = gr.Number(value=42, label="文本随机数")
generate_text_seed = gr.Button("\U0001F3B2")
generate_button = gr.Button("文本生成语音")
text_output = gr.Textbox(label="微调文本", interactive=False)
audio_output = gr.Audio(label="语音")
generate_audio_seed.click(generate_seed,
inputs=[],
outputs=audio_seed_input)
generate_text_seed.click(generate_seed,
inputs=[],
outputs=text_seed_input)
generate_button.click(generate_audio,
inputs=[text_input, temperature_slider, top_p_slider, top_k_slider, audio_seed_input, text_seed_input, refine_text_checkbox],
outputs=[audio_output, text_output, ])
# 启动WebUI
demo.launch(server_name='127.0.0.1', server_port=8089, share=False, show_api=False, )
if __name__ == '__main__':
main()
|